短效代理
隧道代理
套餐购买
提取工具
帮助中心
产品手册
产品介绍
短效代理
隧道代理
常见问题
使用问题
购买问题
产品问题
开发者指南
开发者指南
快速入门
通用功能
API接口
白名单接口
错误码一览
短效代理接口
行业资讯
关于我们
登录
免费注册
控制台
{{ userInfo.sub_user?.name || userInfo.username }}
{{ userInfo.sub_user?.name || userInfo.username }}
个人认证
企业认证
未实名认证
¥
{{ userInfo.money }}
充值
会员中心
未支付订单
退出登录
首页
/
行业资讯
/
反爬越来越猛,隧道代理靠AI调度破局:2026技术趋势全解析
反爬越来越猛,隧道代理靠AI调度破局:2026技术趋势全解析
2026-06-16
大数据采集
IP轮换机制
多线程爬虫
IP资源质量
做数据采集的人今年应该都有一个共同感受:IP换得再勤,该被封还是被封。 这不是错觉。翻一下各大技术论坛今年的帖子,抱怨反爬升级的数量明显比去年多了。而且大家吐槽的重点也在悄然变化。以前是"IP不够用""被封得太快",现在变成了"明明IP是干净的,请求还是过不去"。 这到底发生了什么??反爬在升级,隧道代理又是怎么跟着变的?下面一个一个说。 ## 反爬在升级什么?先看看对面在干嘛 搞清楚隧道代理为什么要引入AI调度之前,得先知道对面的反爬已经进化到什么程度了。 ①**设备指纹深度化。** 早几年反爬主要看IP和请求头,现在越来越多站点开始综合判断浏览器指纹、TLS指纹、TCP连接特征这些东西。技术社区讨论过很多次的一个例子是:同一个IP发出两个请求,一个用的是Chrome 120的TLS握手特征,另一个是Python Requests库的默认特征,系统立刻判定为代理流量,两个请求全部拦截。光换IP没用,请求的"长相"也得对得上。 ②**行为序列建模。** 一些大平台已经在分析用户的浏览路径——正常用户会先看首页、再搜索、再点商品详情,可能还会加购物车。而爬虫通常是直接请求商品详情页或API接口。平台把大量真实用户行为建模之后,对"跳过正常浏览流程直接到达目标页面"的请求标记为高风险。这类风控对代理服务提出的要求已经不只是"IP换不换"的问题,还得配合请求的行为模式做调度。 ③**IP信誉评分体系的普及。** 不少平台已经建立了自己的IP黑名单和灰名单,甚至直接接入第三方IP信誉数据库。一个IP只要在任何一个合作平台上被标记过,在其他平台也会被重点关注。这就要求[代理服务商](https://www.ja.cn/doc/5288.html "代理服务商")必须实时监控IP池中每个IP的信誉状态,一旦发现被标记,立即从活跃池中隔离。 这三件事加在一起,意味着"换IP"这个动作本身已经不够用了。代理服务得变得更聪明,不能只管换,还得知道什么时候换、换成什么样的、搭配什么请求特征一起出去。这就是[隧道代理](https://www.ja.cn/doc/5291.html "隧道代理")开始引入AI调度的根本原因。 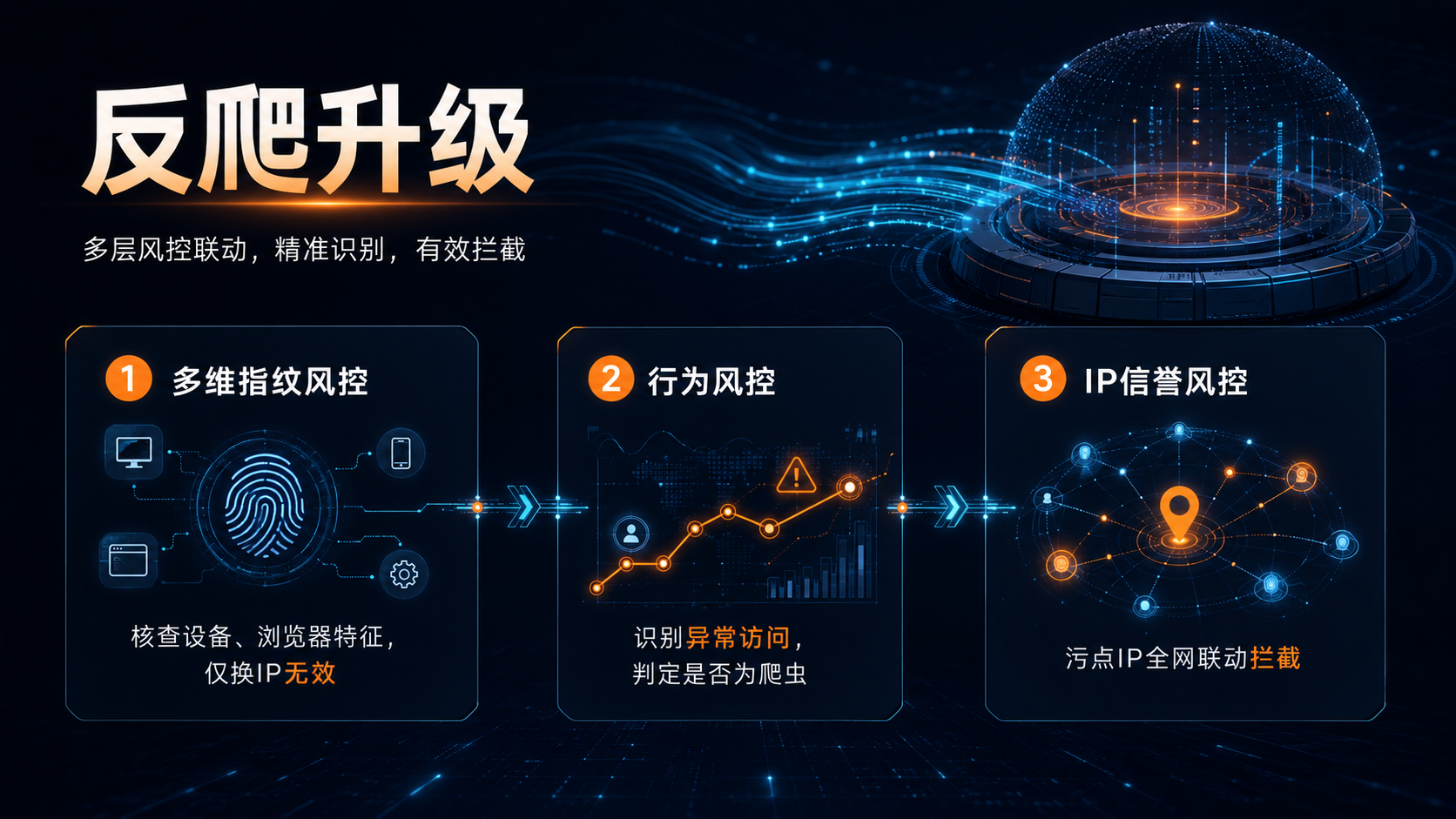 ## 隧道代理的调度到底在调什么?很多人理解错了 很多人对隧道代理的认知还停留在"固定入口、自动换IP"这一层。确实,这是隧道代理的基础能力。连一个网关地址,后端帮你轮换出口IP,省去手动管理IP列表的麻烦。 但如果只做到这一步,和一个带定时器的IP池脚本没什么区别。 现在头部服务商的调度引擎,实际管理的参数远不止IP地址。根据公开的技术文档和从业者的实测反馈,成熟的调度系统至少会同时看这些东西:目标站点的风控等级、当前IP的历史被封概率、请求发起的地理位置匹不匹配、同一IP在过去N分钟内被分配给了多少不同用户、甚至目标站点近期的风控策略有没有变过。 举个能直观感受到的例子:同样请求同一个电商站,凌晨两点和下午三点被分配到的IP段往往明显不同。 原因是调度引擎在根据目标站点的实时风控强度动态调整IP选取策略。下午高峰期风控严,优先分配"干净"的住宅IP;凌晨低峰期风控松,就用成本更低的机房IP。这种调度逻辑如果纯靠人工写规则,几十个站点的排列组合就能让维护成本爆炸,所以现在行业基本都在往机器学习方向走。 ## 智能调度和传统轮换,实际用起来差多少? 道理说够了,说点实在的。 做过多站点[采集](https://www.ja.cn/doc/5294.html "采集")的人应该都遇到过一个矛盾:不同站点的反爬强度差异很大,但传统方案只能设一个统一的轮换频率。比如一个舆情监控项目,每天要从十几个新闻站点拉内容,设成每5秒换一次IP——有几个站点反爬很松,5秒换一次纯属浪费,同一个IP连用十几次都不会触发风控;但另外两三个站点风控很紧,5秒一换根本不够,连续几个请求就弹验证码。想针对每个站点单独写策略可以,但十几个站点各自调参、各自维护,人力成本立刻上来了。 支持智能调度的隧道代理解决的就是这个问题。调度引擎根据每个目标站点的实际响应情况自动调整策略——风控松的站点同一个IP连用十几次,风控紧的站点每次请求都换IP并主动插入随机延时。不需要人去写十几套轮换规则,调度引擎自己在"学"。 从公开的实测数据来看,这种切换带来的成功率提升通常在15到20个百分点左右(从75%-80%提升到92%-95%),而且更省心的一点是不再需要安排人半夜盯监控随时调策略。 但这里有个隐藏成本需要正视:智能调度方案的单价通常比传统轮换贵30%-40%。值不值得切,取决于省下来的人力和避免的数据丢失能不能覆盖这个差价。采集规模大、目标站点多(十个以上)的团队,基本上是覆盖得了的;但如果只是轻量级采集、目标就一两个站点,传统方案可能性价比更高。  ## 必须泼的冷水:AI调度不是万能解药 有些行业文章把AI调度吹得天花乱坠,好像接入了就能100%绕过所有反爬。没那么神,有几个坑需要提前认清。 第一,AI调度好不好使,很大程度上取决于IP池本身的质量和规模。底层IP池如果就是被用烂了的机房IP,再智能的调度也救不了。技术论坛上经常看到这样的吐槽:花了钱用了某家号称"AI智能调度"的服务,结果一查IP池总共就几万个,质量参差不齐,调度来调度去还是那些被标记过的IP,成功率照样上不去。 第二,AI调度需要数据积累期。一个新上线的调度模型,没有足够的历史请求-响应数据来训练,策略选择不见得比一套写得好的固定规则更优。能真正把智能调度做好的,往往是那些运营了至少两三年、日均处理请求量在千万级以上的服务商——因为只有这种量级的数据喂出来的模型,才能覆盖足够多的站点风控模式。 第三,特定场景下手动配置仍然更可靠。如果只采集一个固定站点,而且对这个站点的风控规则已经摸得很透,那一套针对性的轮换策略大概率比通用AI调度好用。AI调度真正拉开差距的场景是"多站点、多场景、规则复杂到人工管理不过来"——到了这种程度,它才真正比人靠谱。 ## 2026年值得关注的几个技术走向 最近技术社区讨论比较多的,有几个方向看起来会先落地: **调度引擎开始管指纹了。** 前面提到,现在反爬不只看IP,还看请求指纹。下一步的隧道代理,调度引擎要管的不仅是分配哪个IP,还要同时决定这个请求搭配什么TLS指纹、什么浏览器指纹、什么请求头组合。调度的输出从单一的"IP地址"变成一个完整的"请求身份包"。据技术社区反馈,已经有一两家厂商的内测功能里出现了这种能力的雏形。 **从"后知后觉"到"提前预判"。** 目前大多数调度引擎是基于历史数据做决策——某个IP被封了,才知道这个站点最近风控收紧了,总是慢一拍。未来的方向是通过主动探测和实时反馈,在风控策略变化的第一时间就感知到,然后立刻调整调度参数。有点像金融里的高频交易系统,拼的是毫秒级的反应速度。 **AIGC训练数据采集的专用方案。** 大模型训练需要的是广泛的、多样化的、覆盖不同地域和语种的数据,跟以前"定点抓某几个站点"完全是两回事。这意味着隧道代理需要在全球范围内调度IP资源,而且要在数据合规性上提供保障。做NLP训练数据的团队对代理服务的核心诉求已经从"别被封"变成了"合规地采到足够多样化的数据"——这个变化,正在把隧道代理的产品边界往外推。  ## 总结 隧道代理这个行业确实到了一个转折点。反爬技术越来越狠,逼得代理服务不得不变聪明,而AI刚好给了一条能走通的路。但技术归技术,最终还是要回到具体业务场景里去验证。别被概念忽悠,多做实测,数据不会骗人。 如果正在做数据采集相关工作,遇到具体技术选型问题欢迎留言讨论。
上一篇
HTTP代理与HTTPS代理的区别是什么?
下一篇
2026 年了,自建代理池还有意义吗?
热门文章
2026 年了,自建代理池还有意义吗?
“清朗”行动之下,隧道代理行业进入合规分水岭
反爬越来越猛,隧道代理靠AI调度破局:2026技术趋势全解析
大模型接入舆情系统后,代理IP的选型逻辑怎么变?
代理 IP 到底贵不贵?一个公式算清你的真实采集成本
代理 IP 在 AI 数据采集中的角色:从工具到基础设施
动态 IP 和静态 IP 有什么区别?采集业务到底该用哪一种?
最新文章
2026 年了,自建代理池还有意义吗?
“清朗”行动之下,隧道代理行业进入合规分水岭
反爬越来越猛,隧道代理靠AI调度破局:2026技术趋势全解析
大模型接入舆情系统后,代理IP的选型逻辑怎么变?
代理 IP 到底贵不贵?一个公式算清你的真实采集成本
代理 IP 在 AI 数据采集中的角色:从工具到基础设施
动态 IP 和静态 IP 有什么区别?采集业务到底该用哪一种?
隧道代理是什么?和普通代理 IP 的核心区别在哪里
代理IP到底是什么,企业做数据采集为什么离不开它
选代理 IP 服务商,哪些参数真正决定你踩不踩坑?