短效代理
隧道代理
套餐购买
提取工具
帮助中心
产品手册
产品介绍
短效代理
隧道代理
常见问题
使用问题
购买问题
产品问题
开发者指南
开发者指南
快速入门
通用功能
API接口
白名单接口
错误码一览
短效代理接口
行业资讯
关于我们
登录
免费注册
控制台
{{ userInfo.sub_user?.name || userInfo.username }}
{{ userInfo.sub_user?.name || userInfo.username }}
个人认证
企业认证
未实名认证
¥
{{ userInfo.money }}
充值
会员中心
未支付订单
退出登录
首页
/
行业资讯
/
代理 IP 在 AI 数据采集中的角色:从工具到基础设施
代理 IP 在 AI 数据采集中的角色:从工具到基础设施
2026-06-09
国内HTTP代理
大数据采集
合规使用规范
场景适配
过去两年,大模型把"训练数据"这件事从一个冷门话题推到了行业聚光灯下。但很少有人认真讨论:这些数据怎么采、采多少、采多稳,正在悄悄重塑上游的代理 IP 行业。 模型团队需要的不再是几千个 IP 跑两周的临时工具,而是覆盖几千个站点、稳定运行几个月、对脏数据零容忍的基础设施。大多数代理服务商还在用过去十年的产品和话术应对,大客户因此在悄悄流失。 ## 先讲一个观察:AI 数据采集和传统爬虫完全是两种东西 代理 IP 这行做久了能感觉到,**"AI 训练数据采集"这个需求和过去十年的爬虫业务,在工程画像上是两类东西。** 传统爬虫的逻辑相对收敛:目标站点几个、字段几个、频率定好。比如电商监控就是几个主流平台、价格库存销量几个字段、每天跑一遍。技术上是"在已知规则下高效执行",需求边界清楚。 AI 训练数据采集的工程画像几乎是反过来的: - **目标站点极度分散**:一个中文大模型预训练数据,可能要覆盖几千个站点——技术博客、垂类问答、行业论坛、政府公开数据、学术资源、新闻媒体。 - **数据非结构化**:要的是"完整的高质量长文本",不是字段。 - **周期长**:一个版本采几个月,下个版本继续。 - **质量要求极高**:脏数据进训练集模型就废了。失败率、覆盖完整度的容忍度比传统爬虫低一个数量级。 **这意味着代理 IP 在 AI 场景下的角色变了。** 传统爬虫场景里,代理 IP 是"工具"——服务商给个池子,客户自己组装使用。AI 数据采集场景里代理 IP 是"基础设施"——要扛得住几千个目标站点的反爬差异、扛得住几个月不间断的稳定运行、扛得住采集团队对"任何一个站点不能挂"的硬性要求。 行业里很多代理服务商还没意识到这个变化。继续按老套路卖——大池子、高轮换、按量付费。结果就是 AI 客户跑两个月发现采集完整度上不去、某几个目标站点持续封禁,最后换服务商。**这两年代理 IP 行业大客户的流失,多半是栽在这个变化上**——产品没跟着客户业务一起演进。 ## 一个 AI 训练数据项目的真实复盘 讲一个2025年下半年的真实案例。 客户做垂类大模型,要做中文技术领域的预训练数据采集。需求: - 目标站点 1200+ 个,覆盖技术博客、问答、论坛、知识库、官方文档 - 日均采集量 2000 万页 - 数据完整度要求 95% 以上 - 持续运行 6 个月以上 - 单页平均文本长度 3000–8000 字(要求拿到完整内容,不能截断) 客户原本用的是另一家代理服务商,跑了一个月之后切换到极安代理。原因是几个核心目标站点(知乎、CSDN、掘金、思否、各类垂直论坛)的封禁率持续上升,到第四周已经压不下来了,数据完整度跌到 72%。 客户那边的工程负责人在前期沟通时有一句话印象很深,原话大概是:**"我们不缺 IP,缺的是能跑得久的方案。"** 这句话其实就把 AI 客户和传统爬虫客户的差别讲透了。 切换到极安代理之后,围绕这个项目的方案调整核心是三件事。 ### **第一件,重新做目标站点的分级。** 之前的供应商和客户都按"站点重要性"分级——大站优先保。这个思路在 AI 数据采集场景下是错的。正确的分级应该按**"站点的反爬代际"**分: - **第一代**(基础频次封禁):大量长尾论坛、垂直社区、个人博客。这类站点占目标的 70%+,技术上最简单,但因为长尾分散,**总量上是 AI 数据的主力来源**。 - **第二代**(IP + 指纹组合识别):主流技术社区、问答平台。占目标的 20% 左右,技术中等。 - **第三代**(行为画像 + 设备指纹 + 风控模型):头部内容平台。占目标的 10% 不到,但单站价值高、采集难度最大。 这三类站点用同一套代理策略是跑不动的。新方案对应极安代理的产品矩阵,重新设计了三套并行的采集通道: | 反爬代际 | 代理策略 | IP 类型 | | -------- | ------------------------------ | -------------------- | | 第一代 | 提取式短效,单 IP 用 2–5 分钟 | 动态短效,按量切换 | | 第二代 | 隧道代理,固定入口轮换 | 隧道,时长粘性 30 秒 | | 第三代 | 隧道代理 + 会话保持 + 指纹模拟 | 隧道,会话级粘性 | 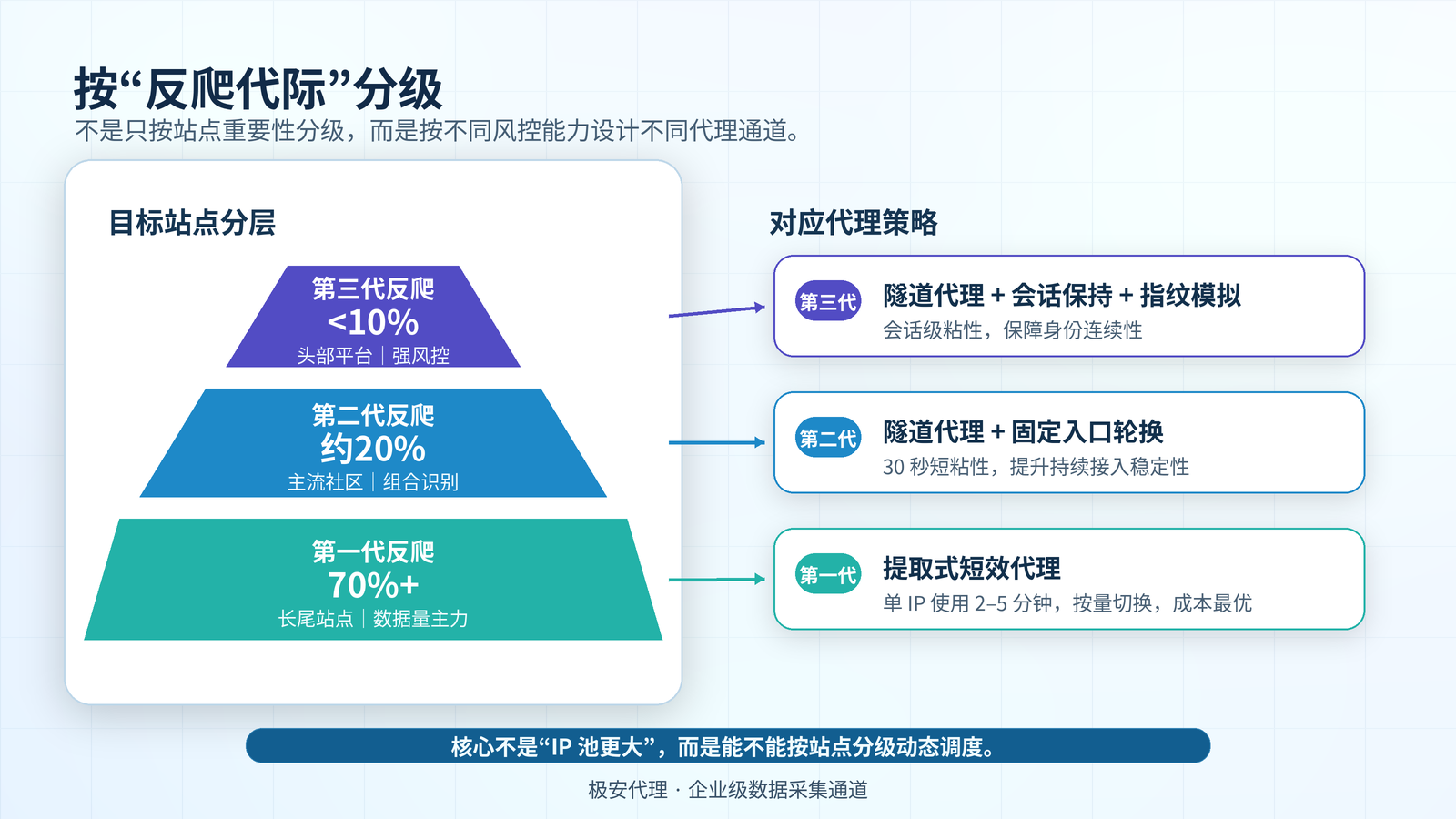 ### **第二件事:把"成功率"这个指标拆掉。** 之前供应商和客户对账用的是"请求成功率"——HTTP 返回 200 就算成。 这个指标在 AI 场景下对评估真实质量帮助有限。 在新方案讨论中,把"成功率"这个指标拆成三个: - **请求成功率**:HTTP 200 的比例 - **内容完整度**:返回内容长度 vs 目标内容长度的比值(按目标站点的页面结构特征预设阈值,例如知乎回答页正文低于 800 字记为不完整) - **训练集可用率**:经过内容质量过滤之后(规则去重 + 模板页过滤 + 5000 条样本人工抽检)之后,真正能进训练集的比例。 跑了一周拉数据出来,结果挺扎心——原来号称 72% 的"完整度",按新指标算下来真正的可用率只有 41%。 中间有 31 个百分点的水分在哪儿?大量请求 HTTP 200 了,但返回内容是反爬替换过的——可能是个登录提示页、可能是被截断的前几百字、可能是个干扰性的相似内容。这些内容如果不做二次过滤直接进训练集,是真的会污染模型。 **这件事其实是 AI 数据采集行业一个普遍的隐性问题——光看 HTTP 成功率会严重高估采集质量。** 而且这个问题之前没人讲,因为传统爬虫场景下不存在这个问题(电商抓不到价格就是抓不到,没有"反爬给你一个假价格"这种事),所以验收习惯没跟上。。  ### **第三件事:长尾站点单独做地域 IP 适配。** 剩下要解决的是覆盖完整度的问题。 传统爬虫的 IP 池逻辑是"保头部站点的纯净度"。AI 场景下这个逻辑是反的——**真正影响数据量的是长尾站点的覆盖率**。70% 的数据来自长尾,长尾跑不通就是数据量不够。 而长尾站点有一个特点:反爬弱,但对 IP 地域分布敏感。很多区域性论坛、地方站、垂直社区,只让特定省份的 IP 访问,或者非本地 IP 直接降速。 针对 1200+ 目标站点,借助极安代理的全国地域 IP 资源,按地域做了精细化分配——华东站点优先用华东 IP、华南站点优先用华南 IP、华北站点优先用华北 IP。 这一步做完,**长尾站点的覆盖完整度从 68% 拉到 94%**。一步带来的提升比前面所有调优加起来都多。  ### 三个月之后的最终数据 - HTTP 成功率:99.2% - 内容完整度:96.8% - 训练集可用率:**91.4%**(之前是 41%) - 单页采集成本下降 58% - 持续运行 6 个月零中断 ## 这个案例里短效和隧道是怎么分工的 回到产品形态的问题。 这个 AI 数据采集项目里,**短效和隧道是同时在用的**,不是替代关系。 - 1200 个目标站点里有 800+ 个是长尾站点(占第一代反爬那部分),用的是**短效代理**。任务批量化、IP 用完即弃、按量提取,成本最优。 - 200+ 个是中等反爬的主流社区,用的是**隧道代理 + 短粘性**(30 秒切换)。隧道的稳定接入更适合需要长期持续抓取的中坚站点。 - 不到 100 个头部高反爬站点,用的是**隧道代理 + 会话粘性 + 指纹工具配合**。这类站点需要保持会话、维持身份连续性,隧道是唯一可行的形态。 **这套混合架构跑通之后带出一个很重要的启发——企业级数据采集业务的供给侧,未来不会是"短效 vs 隧道选一个",而是"按站点分级动态调度两种产品"。** [服务商](https://www.ja.cn/doc/5288.html "服务商")的能力分水岭也会从"有什么产品"变成"能不能帮客户做这种混合调度"。 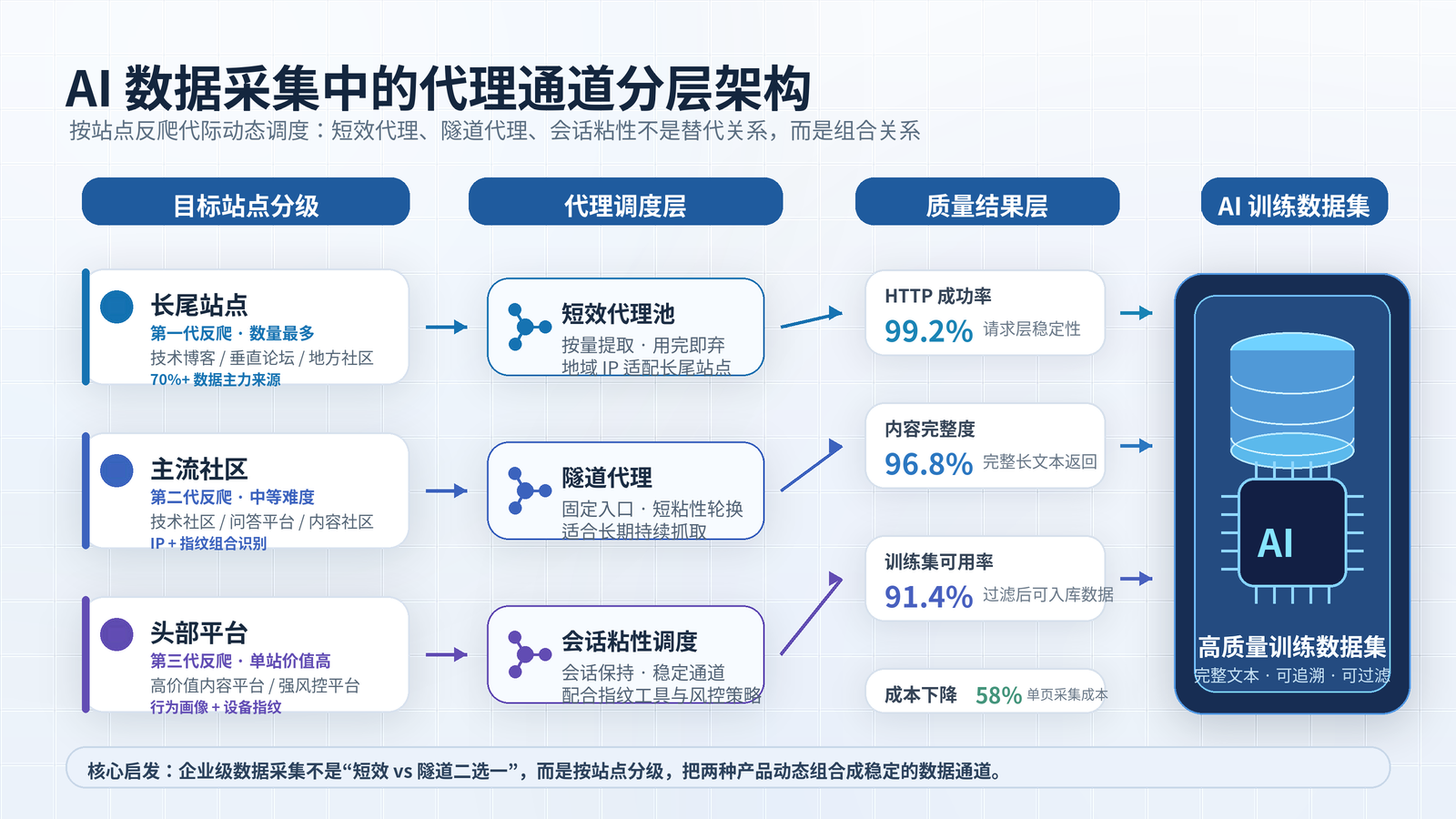 ## 对照案例:舆情监测项目为什么主用隧道 2025年同期还有另一个舆情监测项目也是用极安代理跑下来的,需求和 AI 数据采集表面看很像——都是采中文互联网内容——但跑下来完全是两种产品形态。 舆情项目的特征: - **目标站点固定**:30 多个主流社交平台、新闻媒体、论坛 - **采集频率高**:每个目标 5 分钟一轮,对时效性敏感 - **需要登录态**:很多目标平台要保持会话才能看到完整内容 - **出口要稳**:客户和部分媒体方有数据合作,需要 IP 报备做白名单 这四个特征叠加之后,短效完全不适合: - 站点少且固定,不需要大池子轮换 - 高频短间隔采集,IP 切换成本反而成了负担 - 登录态强依赖,IP 一变会话就断 - 白名单报备要求出口 IP 段稳定,短效的 IP 一直在变没法报备 最后这个客户选用的是极安代理的**[隧道代理](https://www.ja.cn/doc/5291.html "隧道代理") + 长会话粘性 **方案。跑了半年多,可用率 99.8%,舆情监测的 SLA 完全达标。 **这两个项目对照下来会发现——产品形态的选择,从来不是"哪个更好",是"业务特征决定的"。** AI 数据采集的特征是站点海量、长尾分散、长期运行,所以是混合架构、短效为主、隧道用在难点站。舆情监测的特征是站点固定、高频迭代、会话敏感,所以是隧道为主、长粘性、出口稳定。 **这是行业这两年越来越清晰的一个判断——做企业级代理,两条产品线都要做扎实,并且要有能力帮客户做混合架构设计。少一条腿都接不住真正的大客户。** ## 几个行业里讨论不多的趋势 最后讲几个判断。这部分纯属一线观察,不是行业共识。 ### **一、"内容完整度"会变成 AI 数据采集服务商的新分水岭。** 行业现在还普遍用 HTTP 成功率对账。但 AI 数据采集的客户已经在悄悄换指标了——拿"训练集可用率"考核供应商。一个 HTTP 200 但内容是反爬假数据的请求,对 AI 客户来说是负资产。**未来两年,能在合同里承诺"内容质量"的代理服务商,会在 AI 客群里彻底分化出来**。只卖 IP 不管内容的供应商,会慢慢被挤出大客户市场。 ### **二、长尾站点的覆盖能力,正在变成 AI 数据采集的核心竞争力。** 行业大家都在卷头部站点的纯净度。但 AI 数据 70%+ 的量来自长尾。谁能把长尾覆盖从 60% 拉到 90%+,谁就在 AI 客群里有壁垒。**这件事拼的不是 IP 总量,是 IP 的地域分布、运营商分布、以及对长尾站点反爬模式的积累**。这是个"做时间的朋友"的活儿——做了几年慢慢攒下来的,新入场的玩家短时间追不上。 ### **三、"代理 IP"作为单一产品类目,未来可能消解。** 往后看三到五年,企业级数据采集供给侧的主流形态可能不再是卖代理 IP,而是卖**"按场景调优过的采集通道"**——客户告诉服务商目标和需求,服务商交付一整套调优好的代理 + 切换策略 + 反爬应对 + 质量保证。**这是行业从卖资源到卖能力的迁移**。门槛会显著抬高,跨过去的服务商会拿走行业大部分利润,跨不过去的会回到中小客户市场打价格战。 ## 常见问题(FAQ) **Q1:AI 训练数据采集和传统爬虫的核心区别?** 四个维度都不同:目标站点(几个 vs 数千个)、数据形态(结构化字段 vs 非结构化长文本)、周期(短期 vs 数月)、质量容忍度(宽松 vs 低一个数量级)。传统爬虫的 IP 池策略在 AI 场景下往往跑不下来,需要按反爬代际做混合调度。 **Q2:AI 数据采集的合规边界在哪?** 关注四块:站点 ToS 和 robots.txt、版权内容(尤其付费墙后)、个人信息保护(《个人信息保护法》《GDPR》等)、特定保护类目(医疗、未成年人)。代理 IP 作为网络工具中立,合规责任在采集方,跨境训练和商用发布尤需谨慎。 **Q3:为什么 HTTP 成功率不能作为 AI 数据采集验收指标?** 反爬可能返回 HTTP 200 但内容是干扰数据。本文项目里号称 72% 完整度按真实可用率算只有 41%。应改用"训练集可用率"——经过滤和人工抽检后真正能进训练集的比例。 **Q4:为什么要重视长尾站点?** 中文预训练 70%+ 数据量来自长尾。把长尾覆盖率从 60% 拉到 90%,比把头部纯净度从 95% 拉到 98% 对总数据量贡献大得多。长尾真正的难点是地域 IP 适配。 **Q5:怎么评估服务商能不能承接 AI 数据采集项目?** 看三件事:能否同时提供短效和隧道两条产品线并做混合调度;IP 池地域和运营商分布是否足够细;能否在合同里就内容质量做有意义承诺。三条不全,在 AI 客群里很难跑长期项目。 ## 透明度声明 - 本文案例数据来源于极安代理 2025 年实际服务项目,客户身份及业务细节已脱敏处理,核心采集指标和方案路径未做修改。 - 文中所述方法在该案例场景下经实际验证,但具体到不同业务、不同目标站点组合,效果会有差异。 - "几个行业里讨论不多的趋势"一节为基于在手项目样本的预测性判断,不构成投资或采购建议。
上一篇
HTTP代理与HTTPS代理的区别是什么?
下一篇
2026 年了,自建代理池还有意义吗?
热门文章
隧道代理是什么?和普通代理 IP 的核心区别在哪里
代理IP到底是什么,企业做数据采集为什么离不开它
选代理 IP 服务商,哪些参数真正决定你踩不踩坑?
什么是 HTTP 代理?搞数据采集前先把这件事讲透
极安代理是什么?一家面向企业数据业务的代理 IP 服务商
数据采集效果不好,为什么要先检查代理 IP?
短效代理是什么?适合哪些企业数据采集场景?
最新文章
2026 年了,自建代理池还有意义吗?
“清朗”行动之下,隧道代理行业进入合规分水岭
反爬越来越猛,隧道代理靠AI调度破局:2026技术趋势全解析
大模型接入舆情系统后,代理IP的选型逻辑怎么变?
代理 IP 到底贵不贵?一个公式算清你的真实采集成本
代理 IP 在 AI 数据采集中的角色:从工具到基础设施
动态 IP 和静态 IP 有什么区别?采集业务到底该用哪一种?
隧道代理是什么?和普通代理 IP 的核心区别在哪里
代理IP到底是什么,企业做数据采集为什么离不开它
选代理 IP 服务商,哪些参数真正决定你踩不踩坑?